实时语音交互大模型
关注指标
- 语言模型参数量
- 首次响应延迟
- 是否支持复杂互动:如打断、主动对话、Non-awakening Interaction
- 是否支持多模态输入
- 所需算力
整理: https://github.com/AudioLLMs/Awesome-Audio-Large-Language-Models
VITA(开源)
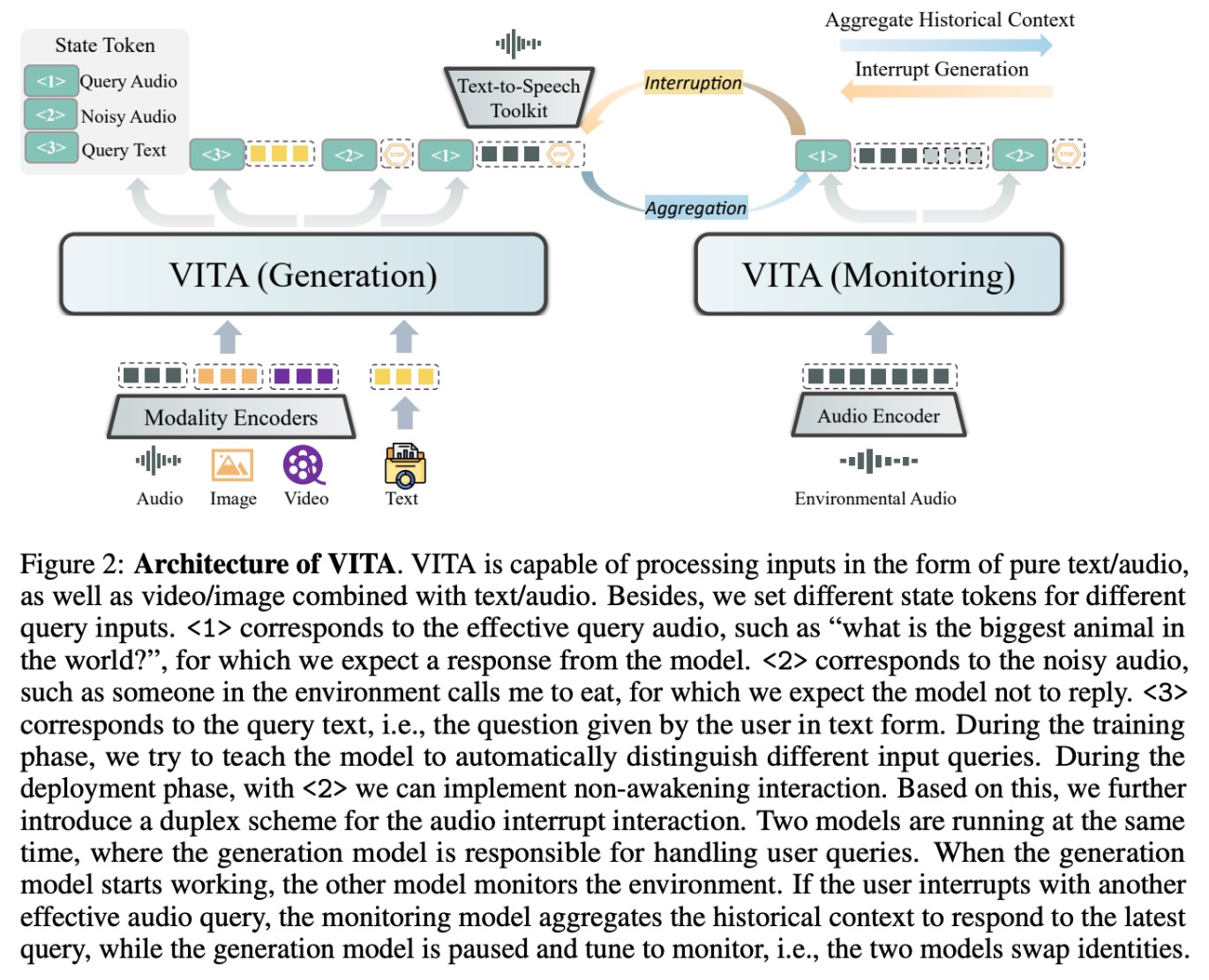
- 语言模型参数量
- Mixtral 8×7 B: 7 billion parameters
- 首次响应延迟
- 首次响应延迟一般在1-2秒以内。
- 是否支持复杂互动:
- 支持打断和主动对话
- 支持 Non-awakening Interaction
- 是否支持多模态输入
- 支持多模态:视频、图片、文本、音频
- 所需算力
- 需要高性能计算设备。“Use high-performance GPUs for deployment. In the demo video, we use 4 Nvidia H20 GPUs. A800, H800, or A100 will be much better.”
MoshiChat(开源)
代码: https://github.com/kyutai-labs/moshi
模型: https://huggingface.co/collections/kyutai/moshi-v01-release-66eaeaf3302bef6bd9ad7acd
报告: https://kyutai.org/Moshi.pdf
发布时间:2024.07.04
- 语言模型参数量
- Moshi 使用了 7 B 参数的 Temporal Transformer
- 首次响应延迟
- Moshi 理论延迟为 160 ms,实践中在
L4 GPU上可低至 200ms
- Moshi 理论延迟为 160 ms,实践中在
- 是否支持复杂互动
- Moshi 支持双向流音频对话,并通过预测自身的“内在独白”来提升生成质量
- 未明确提及打断或 Non-awakening Interaction(非唤醒交互)
- 模型的双流交互设计可能有助于支持主动对话
- 是否支持多模态输入
- 主要处理语音和文本,未提及多模态输入支持
- 所需算力
- PyTorch 版本需要 24 GB 以上的 GPU 内存
- Rust 版本后端需安装 CUDA,macOS 支持 Metal 加速
LLaMA-Omni(开源)
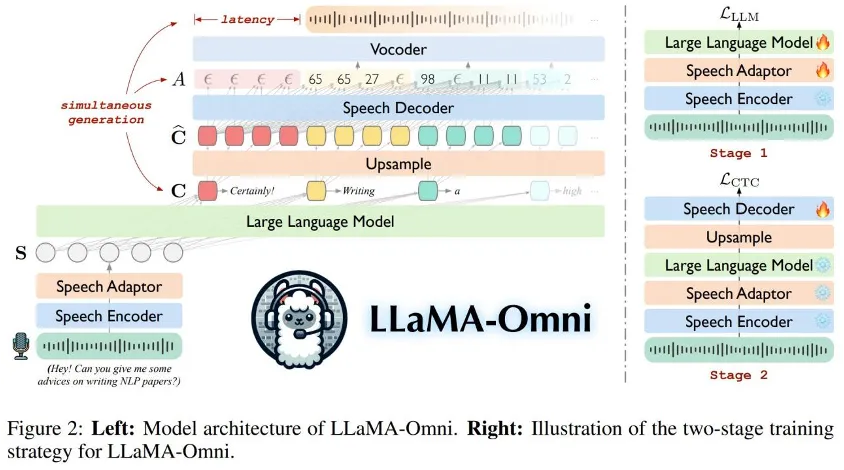
- 语言模型参数量
- Llama-3.1-8 B-Instruct
- 首次响应延迟
- 226 ms
- 是否支持复杂互动
- 包含打断、主动对话
- Non-awakening Interaction
- 是否支持多模态输入
- 支持
- 所需算力
- 训练使用 4 个 GPU,时长小于 3天
- Speech Encoder:
Whisper-large-v3
GLM-4-Voice(开源)
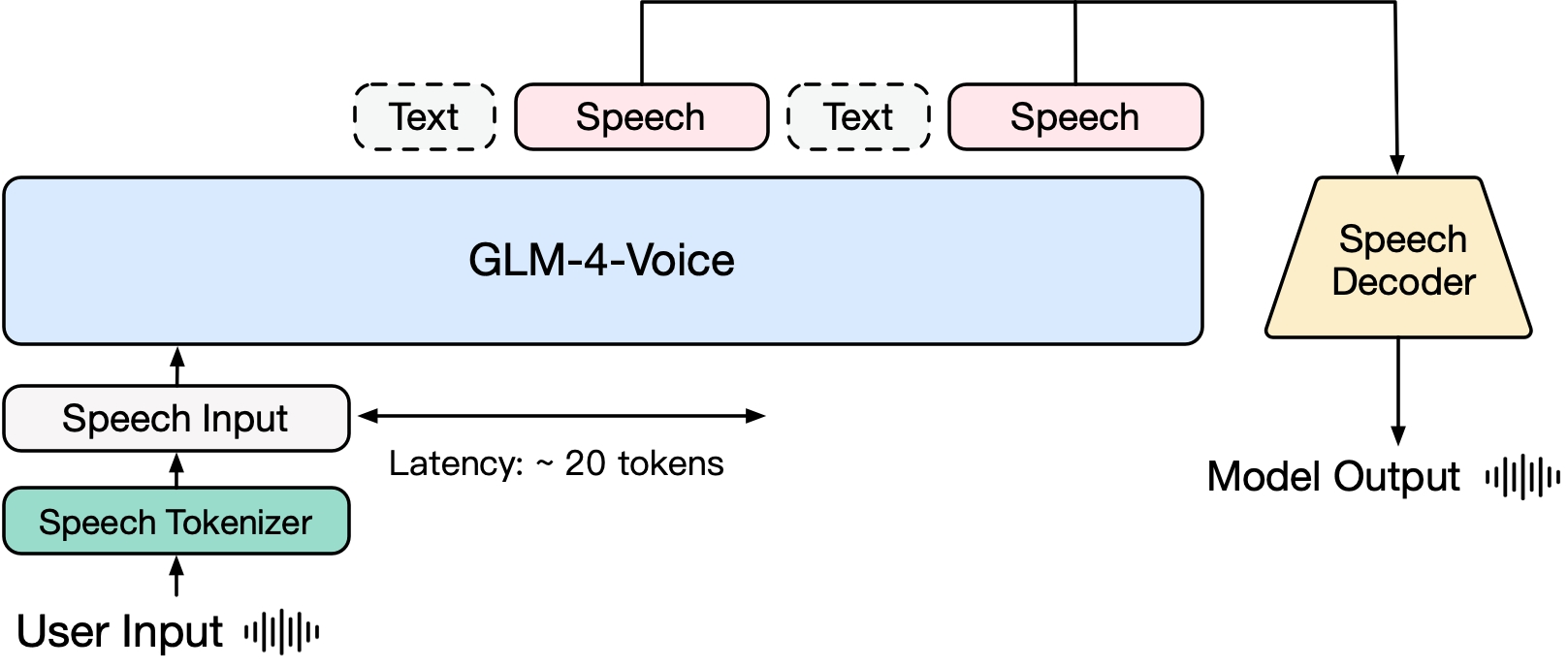
- 语言模型参数量
- GLM-4-9B 模型
- 首次响应延迟
- 最低只需生成 20 个 token 即可开始语音合成
- 是否支持复杂互动
- 支持复杂的语音互动功能,包括情绪调节、语速变化、方言切换等。
- 是否支持多模态输入
- 支持
- 所需算力
- 支持 Int4 量化和 BF16 精度
Freeze-omni (开源)
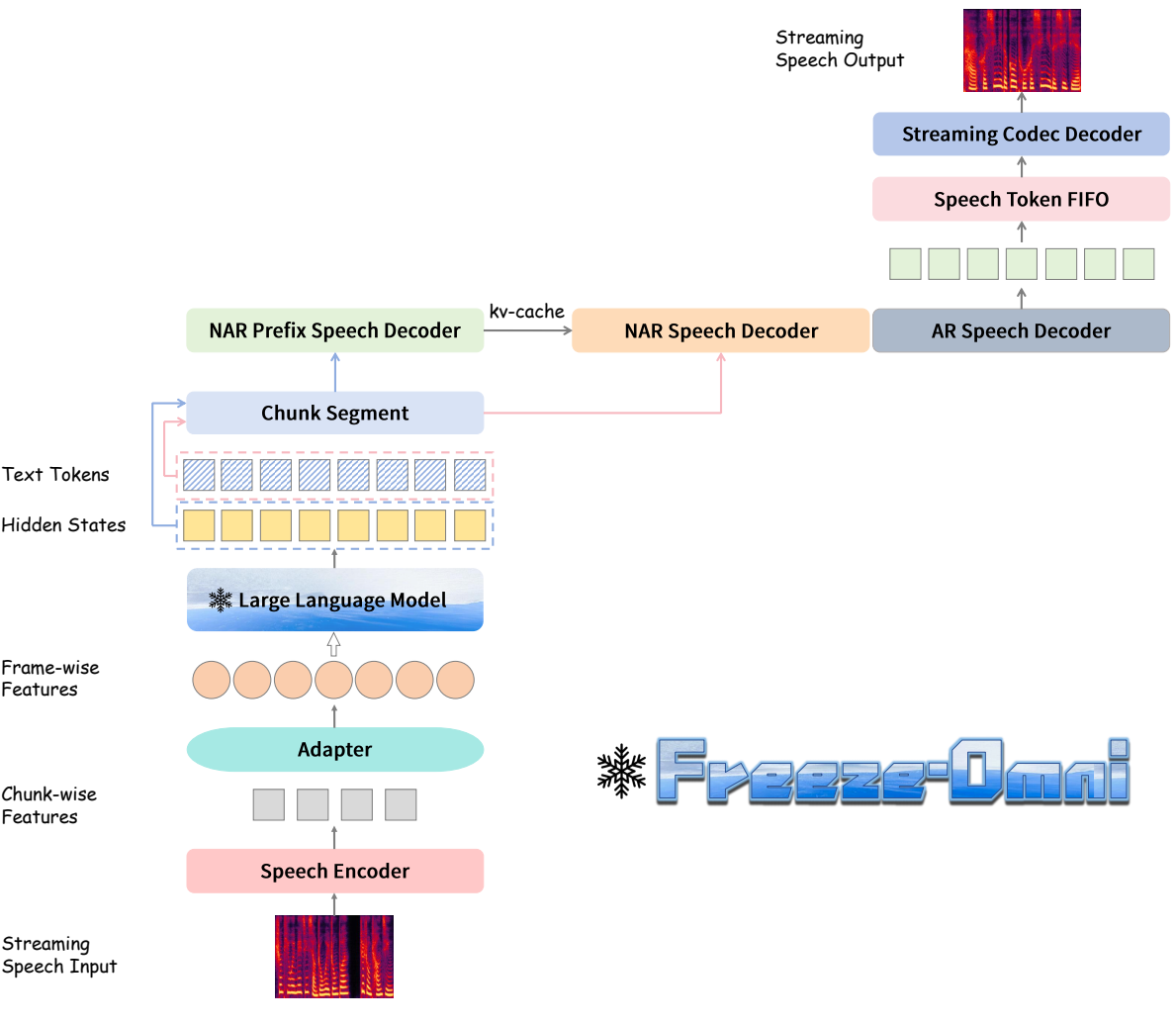
- 语言模型参数量
- 使用了 Qwen2-7B-Instruct 作为核心语言模型
- 首次响应延迟
- 800ms
- 是否支持复杂互动
- 引入了块级状态预测(Chunk-level State Prediction),可以预测用户是否需要打断对话。这种功能支持复杂交互场景,如主动对话和打断行为。此外,其设计还支持全双工对话模式(Duplex Dialogue)。
- 是否支持多模态输入
- speech to speech
- 所需算力
- 暂无
Mini-Omni (开源)
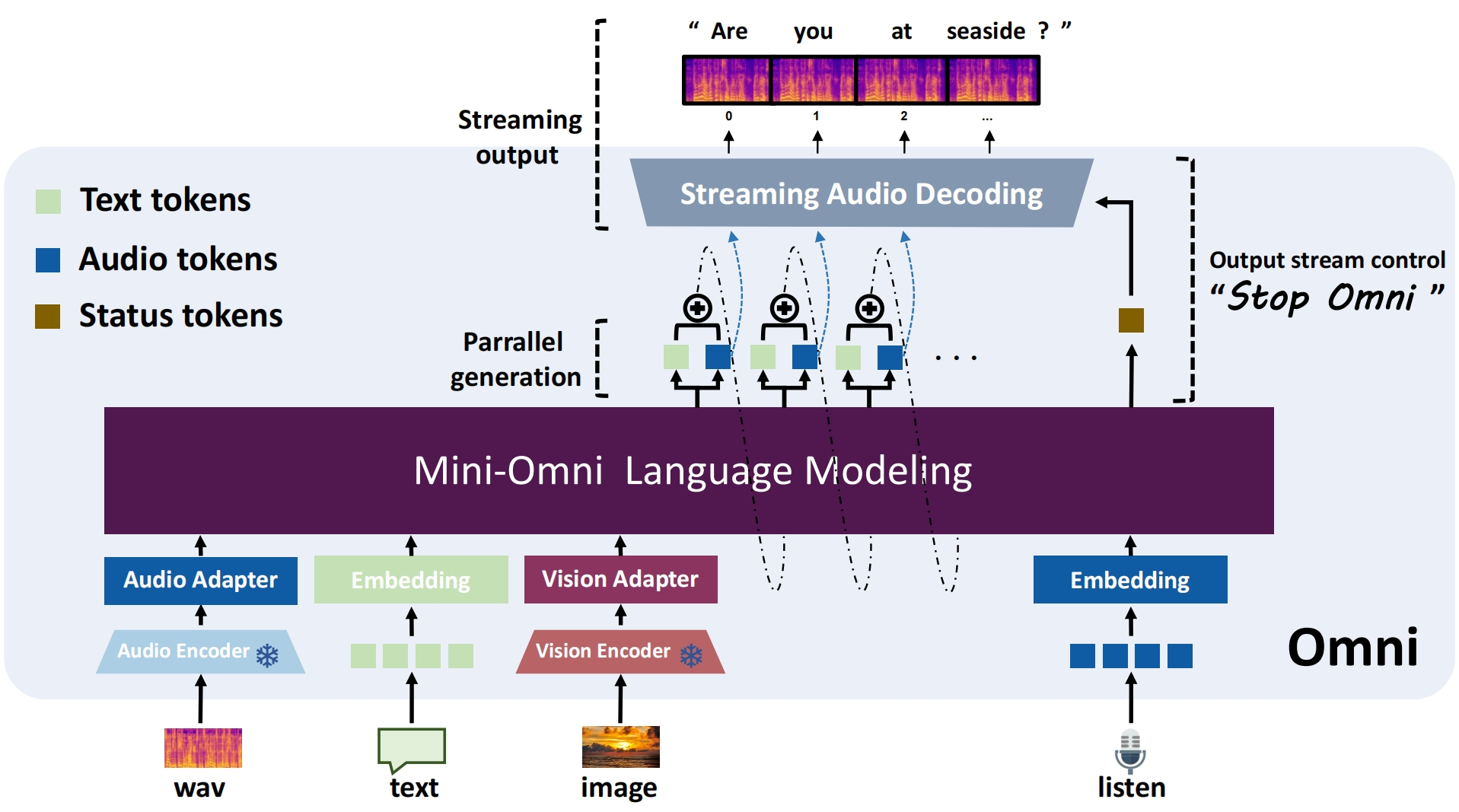
- 语言模型参数量
- Qwen2å
- 首次响应延迟
- 暂无
- 是否支持复杂互动
- 支持复杂互动,包括:打断机制:支持用户在语音生成过程中打断。主动对话:允许模型根据上下文主动进行回应。Non-awakening Interaction:提供了连续对话的能力,无需唤醒词触发。
- 是否支持多模态输入
- 输入音频、文本、图片
- 所需算力
- 暂无
- 支持英文输出
Qwen 2-Audio (开源)(非实时对话)
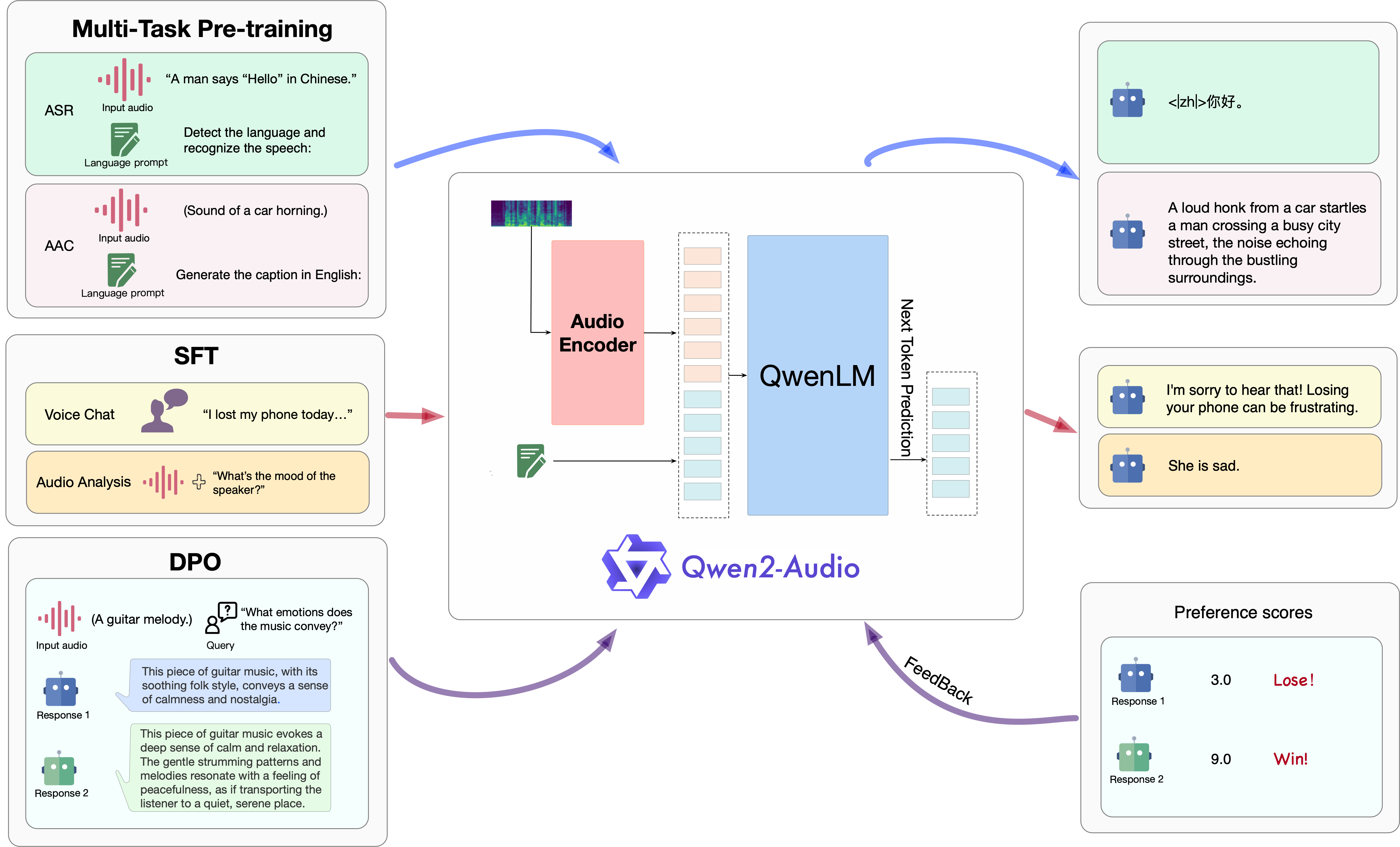
- 语言模型参数量
- 7B
- 首次响应延迟
- x
- 是否支持复杂互动
- x
- 是否支持多模态输入
- 输入音频、文本
- 所需算力
- 暂无